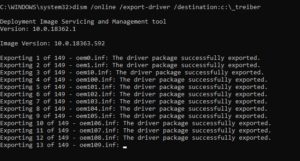
Im aktuellen Fall war leider ein reguläres Wiederherstellen des Systemabbildes nicht möglich, weshalb ich das System mit Hilfe der vhd-Dateien manuell wiederhergestellt habe. Retter in der Not war für mich das kostenfreie Tool „Minitool Partition Wizard“.
Folgende Schritte wurden an einem unabhängigen Rechner mit Windows 8 ausgeführt, an dem zusätzlich die neue Festplatte (120GB) und der Backupdatenträger mit dem Windows-Systemabbild, angeschlossen war.
Schritt 1: Mounten der Boot-vhd
Um Zugriff auf die Dateien des Systemabbildes zu bekommen, müssen erst die Zugriffsrechteerlangt werden. Dies kann durch das System erfolgen, oder man macht es manuell über den Reiter „Sicherheit“ der Datei-Eigenschaften. Im eigentlichen Backup-Verzeichnis sind dann mehrere Dateien, von denen für dieses Beispiel nur die vhdx-Dateien von Bedeutung sind.
![]()
![]()
Zuerst muss die Bootpartition vom Windows Backup kopiert werden.
In unserem Fall ist es die Datei b6d883ad-0000-0000-0000-100000000000.vdhx
![]()
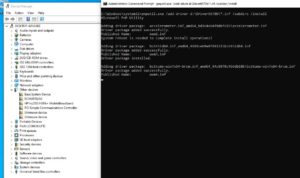
Eingebunden wird die virtuelle Festplatte z.B.: über diskpart.
Der Befehl zum Einbinden lautet:
select vdisk file=“E:\WindowsImageBackup\DESKTOP-KV073KP\Backup 2017-10-12 080847\b6d883ad-0000-0000-0000-100000000000.vdhx”
und
attach vdisk
![]()
ab jetzt ist die Festplatte im System eingebunden.
Schritt 2 Kopieren der Bootpartition
Jetzt starte ich das „Minitool Partition Wizard“ und sehe hier nun mehrere Festplatten.
Wichtig ist für mich, als Quelllaufwerk, die eingebundene virtuelle Festplatte und das 120GB große Ziellaufwerk
![]()
Sollte das Ziellaufwerk eine Partition besitzen, so lösche ich diese jetzt
![]()
![]()
Jetzt kopiere ich die 500MB große Bootpartition auf das Ziellaufwerk
![]()
![]()
![]()
Damit die Aktion auch ausgeführt wird, bestätige ich das mit „Apply“
![]()
![]()
![]()
![]()
Schritt 3: mounten der System-vhd
Um nun die Systempartition zu kopieren, unmounte ich zuerst die virtuelle „Boot“-Disk. Grundsätzlich müsste ich das nicht machen, da man mehrere virtuelle Festplatten mounten kann, aber damit es übersichtlich bleibt, mach ich diesen Zwischenschritt.
Der Befehl lautet
Detach vdisk
![]()
Jetzt wähle ich die virtuelle „System“-Disk aus dem Backup aus und mounte diese mit dem Befehl:
select vdisk file=“E:\WindowsImageBackup\DESKTOP-KV073KP\Backup 2017-10-12 080847\b6d883ad-0000-0000-0000-501f00000000.vdhx”
und
attach vdisk
![]()
![]()
Nach einem erneuten Einlesen der Festplatten im „Minitool Partition Wizard“, erkennt man die eingebundene virtuelle Festplatte
Schritt 4: Verkleinern der Partition
Da die ursprüngliche Festplatte 180GB hatte, passt diese nun nicht auf die neue, kleinere, Festplatte.
Dazu muss man die Partition verkleinern.
Grundsätzlich geht das auch mit dem Diskpart-Befehl „Shrink“, jedoch kann Diskpart die reservierten Bereiche von Dateien (z.B.: Pagefile.sys oder Schattenkopiebereich) nicht verkleinern.
Deshalb nehme ich auch hier wieder das „Minitool Partition Wizard“ um die Partition in der virtuellen Festplatte zu verkleinern.
![]()
![]()
![]()
![]()
![]()
![]()
Hinweis:
Sollte sich die virtuelle Festplatte nicht genug verkleinern lassen, weil z.B.: viele Dateien darauf sind (Musik Bilder), könnte man die Vdisk noch in das System einbinden (Befehle) und die Dateien auf eine externe Festplatte verschieben, so dass genug Platz für die Verkleinerung vorhanden ist.
Schritt 5: Kopieren der Systempartition
Jetzt kann ich, wie unter Schritt 2, die Systempartition auf das Ziellaufwerk kopieren.
![]()
Hier kann ich auch gleich wieder auswählen, wie groß die Partition sein soll (anpassen an Plattenplatz). Vermutlich hätte ich in diesem Schritt auch eine zu große Partition verkleinern lassen können, aber ich mache es lieber Step by Step.
![]()
![]()
![]()
![]()
![]()
Schritt 6: Partitionen korrigieren
Als nächstes kontrollieren wir den Partitionstyp. Da es sich um ein MBR-System handelt sollten die Boot- und Systempartition als „Primary“ gesetzt werden.
![]()
Die Boot-Partition muss zusätzlich noch als „Aktiv“ gesetzt werden.
![]()
Und nicht vergessen, auf „Apply“ klicken um die Aktionen auch auszuführen.
![]()
![]()
![]()
![]()
Jetzt habe ich beide Partitionen wieder auf einer neuen, physischen, Platte und kann diese nun in den Laptop/Rechner einbauen.
Schritt 7: Bootsektor reparieren
Nach dem die Festplatte im Rechner eingebaut ist und der Rechner gestartet wird, endet der erste Start sehr wahrscheinlich in einem Fehler.
![]()
Da sich die Partitionen geändert haben, muss die Bootroutine/der Bootsektor repariert werden.
Dazu starte ich noch einmal die Reparatur-/Installations-CD mit den Reparaturoptionen.
![]()
Unter Problembehandlung -> Eingabeaufforderung kann man eine Konsole öffnen ….
![]()
![]()
…und folgende Befehle eingeben.
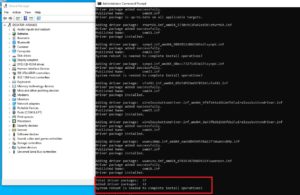
Bootrec /fixmbr
Bootrec /fixboot
Bootrec /rebuildbcd
![]()
Der Befehl „/bootrec /rebuildbcd“ bringt als Auswahl alle gefundenen Windowssysteme, welche eingebunden werden können. Da in diesem Beispiel nur ein System vorhanden war, wird auch nur eines angezeigt, welches mit „J“ (Ja) oder „A“ (alle) bestätigt werden kann.
Mit dem Befehl Exit beendet man die Konsole und kann nun den Rechner neu starten.
![]()
Der Rechner sollte nun ohne Probleme starten.
![]()
Ein Aufruf des Diskmanagements zeigt nun die Festplatte mit (in diesem Fall) 120GB Größe an.
![]()
Es hat also geklappt, ein nicht wiederherstellbares Systemabbild, welches von einer 180GB großen Festplatte gemacht wurde, auf eine kleinere Festplatte, funktionsfähig, zu kopieren.
Man kann vom Windows-Systemabbild halten, was man will – ich finde es ganz ok. Und im Gegensatz zu anderen Softwarepaketen, bekommt man hier eine virtuelle Festplatte (vhd), welche man im Notfall auch anderweitig wiederhergestellt bekommt.